Dropshipping SEO makes your Shopify store successful

Over the years, Shopify has become a leading platform for entrepreneurs looking to tap into the dropshipping model. This approach allows sellers to offer a wide range of products without the hassle of managing inventory or logistics. Understanding how to use SEO effectively is crucial if you want to fully take advantage of the opportunities dropshipping with Shopify provides.
Understanding dropshipping on Shopify
Dropshipping is a distinct way for sellers to approach ecommerce. Dropshipping helps you start and scale an online retail business with minimal financial risk by eliminating the need for inventory management and upfront product investments.
What is dropshipping?
Dropshipping is a fulfillment method where a seller operates an online storefront without holding any physical inventory. Instead, the seller partners with third-party suppliers who manage inventory and logistics, shipping products directly to the end customer. This business model minimizes upfront costs and overhead, enabling you to offer a wide array of products and swiftly adapt to market trends. However, success in dropshipping hinges on strategic supplier relationships, effective digital marketing, and exceptional customer service to meet consumer expectations.
Key benefits of dropshipping
It’s very easy to build an online business based on dropshipping. It doesn’t cost that much to get started. Since there’s no need to purchase inventory upfront, you can start your businesses with less capital.
This business offers great flexibility and scalability. With no physical inventory, you can easily add or remove products and scale your business according to demand. The same goes for the choice of products. Access to huge numbers of products from suppliers worldwide allows you to diversify your offerings and cater to customer needs.
Last but not least, it doesn’t matter where you are located. You can manage your online business from anywhere worldwide with an internet connection.
The ethics of dropshipping
Dropshipping can sometimes raise questions about ethics, especially as more people care about sustainability and fair treatment. As a dropshipper, you can positively impact by choosing suppliers who treat their workers well and use environmentally friendly materials. This means offering products made under fair conditions and that don’t harm the environment. Being clear about your commitment to these values can help you earn the trust of customers who care about making responsible choices.
Sustainable packaging and efficient shipping methods can further show your dedication to protecting our planet. Focusing on ethical practices and following rules and regulations helps you build a business that thrives and supports the well-being of people and the environment.
You can build a successful dropshipping business, but it often requires more dedication and effort than many initially expected. Although dropshipping takes out the logistics part, the other challenges of launching and running an ecommerce business remain. As the owner, you’re tasked with handling returns, managing repair or warranty issues, responding to customer inquiries, and ensuring your products are both high quality and legally compliant. These are the kind of responsibilities many frequently underestimate.
Why choose Shopify for dropshipping?
Shopify is a flexible and user-friendly ecommerce platform that makes the dropshipping process easier. It offers seamless integration with various dropshipping apps, allowing sellers to easily add products to their stores. Shopify’s expansive ecosystem supports everything from payment processing to marketing, making it an ideal choice for dropshippers of all experience levels. With Shopify, you can start a dropshipping business with minimal investment.
How to start dropshipping on Shopify
Select a niche that aligns with your interests and market demand to start dropshipping with Shopify. Research potential products and reliable suppliers using Shopify’s app store to find tools for product selection and order fulfillment.
Once your store is set up, create an engaging user experience and optimize your product listings. Effective marketing strategies should also be implemented to attract and retain customers.
Choosing Shopify as your dropshipping platform gives you access to a powerful toolset. These tools help you simplify your operations and enhance your business’s growth potential. Whether starting from scratch or looking to scale an existing venture, Shopify gives you the flexibility and support you need to thrive in ecommerce.
A quick start guide on how to drop ship on Shopify
Starting a dropshipping business on Shopify is straightforward. Here’s a step-by-step guide to get you started:
- Create a Shopify account. Go to Shopify’s website and sign up for a free trial. Once you’re ready to launch, choose a pricing plan that suits your business needs.
- Select a niche and products. Research potential niche markets that interest you and have demand. Use tools like Google Trends and market research to select products that appeal to your target audience.
- Find reliable suppliers: Use Shopify’s app store to find dropshipping apps like Zendrop or Spocket to source products. Choose suppliers known for quality products and reliable shipping.
- Set up your Shopify store. Customize your store with a memorable name and logo. Use Shopify’s themes to design your storefront and create a seamless shopping experience.
- Add products to your store. Import products from your dropshipping app to your Shopify store. Write detailed product descriptions and set competitive pricing.
- Configure payment and shipping settings. Set up payment gateways like PayPal or Shopify Payments and determine shipping rates and options that suit your business model.
- Launch your store. Review all settings and ensure everything functions smoothly. Publish your store and start marketing to attract customers.
SEO is key for Shopify dropshipping success
If you are in the dropshipping business, you are probably not alone. Even if you have picked a good niche, there’s still competition. To get traffic and potential customers, you need SEO (Search Engine Optimization). Shopify SEO is crucial for the success of any dropshipping store.
With SEO, you optimize your online store to improve its visibility in search engine results. The goal is to attract organic traffic without relying heavily on paid advertising. If you implement these SEO strategies well, you can significantly enhance visibility, drive traffic, and increase sales for your store.
SEO strategies for Shopify dropshipping
SEO for drop shippers is not that different from other types of ecommerce SEO. The main goals are getting your site structured properly, well-optimized in terms of performance, and filled with excellent, well-researched, and targeted content. This will help Google find, index, and rank your products.
But remember that getting Google to index and rank brand-new websites is harder than ever. Getting Google to see your site positively takes a lot of work. It will take quite a while before every one of your products is indexed—if that even happens. Be sure to set up a Search Console account to see your store’s indexing status and use the feedback provided to improve your store.
Last but not least, you should always monitor what you are doing. Analyze your SEO performance using tools like Google Analytics and Shopify Analytics. Monitor key metrics such as organic traffic, engagement, and conversion rates — find issues, fix and improve.
Keyword research and strategy
Keyword research is key in all types of SEO. Use tools like Google Keyword Planner, Ahrefs, and Semrush to identify relevant keywords that potential customers are searching for. Focus on long-tail keywords that reflect specific search intents, such as “eco-friendly yoga mats” or “durable waterproof hiking boots for women.” After that, develop a keyword map that aligns with your product categories and pages, and make sure that each page targets specific keywords without overlap.
On-page SEO optimization
Optimizing individual pages and writing unique content is a major part of drop shipper SEO. Write unique and engaging product descriptions highlighting each product’s benefits and features. Avoid using generic manufacturer descriptions to ensure originality and relevance.
Next, structure your content with headers and subheaders. Use H1, H2, and H3 tags to structure your content. Each page should have a clear hierarchy, with primary keywords in the H1 tag and supporting keywords in subheaders.
Write compelling product titles and meta descriptions that include target keywords. Use tools like Yoast SEO for Shopify to optimize these elements, and make sure they are engaging and informative.
Technical SEO
For the technical part of the story, focus on site speed and mobile optimization. Make that your Shopify store loads quickly and is mobile-friendly. Use tools like Google PageSpeed Insights to identify and fix performance issues. Also, make sure there are no security and trust issues on your website. Do make sure your site is accessible and complies with web accessibility standards.
Image optimization
Image SEO is a big part of SEO for dropshippers. Use unique images if possible. Make sure images are compressed and optimized for fast loading times without compromising quality. Shopify does a lot of this by default, but it doesn’t hurt to keep an eye on it. Also, use descriptive file names and alt attributes for all product images. This improves image search visibility and enhances accessibility for users with visual impairments.
Content marketing and blogging
You should invest in content marketing to help rank for more terms and show authority. Develop a content marketing strategy with a blog featuring informative and engaging content related to your niche. Topics could include “The Benefits of Sustainable Fashion” or “How to Choose the Right Yoga Mat.” Use internal links within blog posts to direct readers to related product pages, enhancing the user experience and SEO value.
Schema markup and rich snippets
Proper schema structured data implementation for your products is essential if you want them to stand out in the search results. Add product and related properties to your schema markup to provide search engines with easy-to-understand data about your products. This can enhance search result listings with rich snippets, such as product ratings, shipping policies, and prices.
Building quality backlinks
Focus on acquiring high-quality backlinks from authoritative and relevant websites. Engage in guest blogging, participate in industry forums, and collaborate with influencers to gain valuable links. Avoid blackhat tactics like buying links or using link farms, as these can lead to penalties from search engines.
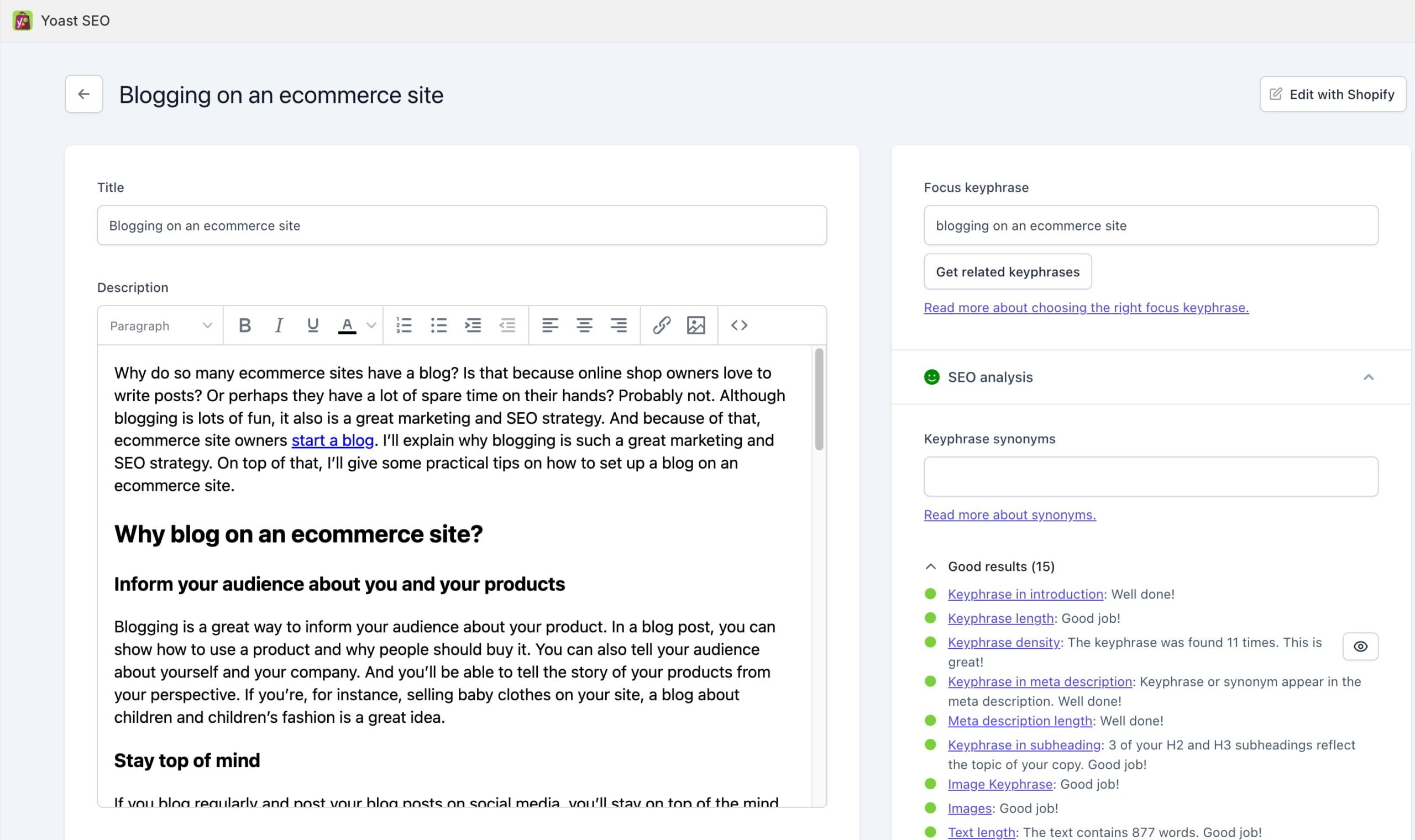
Making the most of Yoast SEO for Shopify
Use the Yoast SEO app for Shopify to streamline your SEO efforts. This tool offers insights and recommendations for optimizing content, managing meta tags, and improving readability, making it easier to implement effective SEO strategies. It even has AI-powered tools to help you write titles and meta descriptions.
More SEO tips
There’s always more to do with Shopify SEO, so keep working on your dropshipping store. For instance, if your dropshipping store has a local component, optimize for local SEO by setting up a Google My Business profile and ensuring consistent NAP (Name, Address, Phone Number) information across directories.
You can also create specialized landing pages for specific campaigns or product categories. These pages can target niche keywords and provide a focused experience for visitors, improving conversion rates.
AI and automation tools for dropshipping SEO
It’s 2024, so you can use AI tools to enhance your SEO strategy and speed up the work. Use AI to generate content ideas, optimize product descriptions, and analyze competitive keywords. Remember to give it the human touch, though!
You need SEO to succeed with Shopify dropshipping
SEO is an important component of a successful Shopify dropshipping business. While it requires patience and consistent effort, the rewards for increased visibility and sales potential are significant. Implementing these SEO strategies, including tools like Yoast SEO for Shopify, helps you position your Shopify store for long-term success in the dropshipping business.
